Earlier this year I spent a few weeks researching, testing and re-building the search functionality for the Financial Times website. It started as an extracurricular pet-project but after some lobbying became a full-time task.
This is intended as a general guide for non-experts trying to gain an understanding of full-text search. I’ve tried to cover the important concepts we had to learn, implement, re-implement and endlessly explain during our short project.
I’ve tried to convey the why rather than the how. It’s not a exploration of any specific technology and there are no code examples. This isn’t because I’m trying to protect any secret sauce, I just don’t think many of the difficult problems were solved by lines of code.
So, we all rely on search engines to navigate the Web and provide immediate answers. However, despite this dependence on and constant use of, I’m far from a search expert and it turns out that there are very few of those…

Animation by Mert Keskin.
1. Search at the FT
1.1 The problem
At the time of writing this, we have 720,000 unique pieces of content available on the main FT.com site, with a further 1000 items being added each week. If the curated home and section pages don’t have what our users want to read then it is possible to browse the 85,000 list pages we surface for every company, person or topic we’ve ever written about.
But that’s not very convenient. People rely on the FT not only for news, but also as a tool for their work. We really need good search functionality.
When we relaunched our new website in late 2016 we used the same search APIs that powered the old website, but with more limited functionality. Some features had been overlooked to meet our relaunch date and it was no longer possible to search for content that had changed format during the switchover.
We received a regular drip feed of complaints…
The new search facility is ABSOLUTELY DREADFUL!”
Finding what you want on the Web is so often frictionless that this just wasn’t good enough. We found out that our paying users and FT colleagues were resorting to Google to find content on our site. So, couldn’t we just do that too?
1.2 Why not use Google?
A company with gazillions of dollars, 20 years of experience, hundreds of highly qualified engineers and a deep understanding of the entire World Wide Web must be able to provide the best search experience for your site, right?
Well… this article doesn’t end abruptly here. Google’s near sentient Web search is astounding but — crucially — it really lacks context.
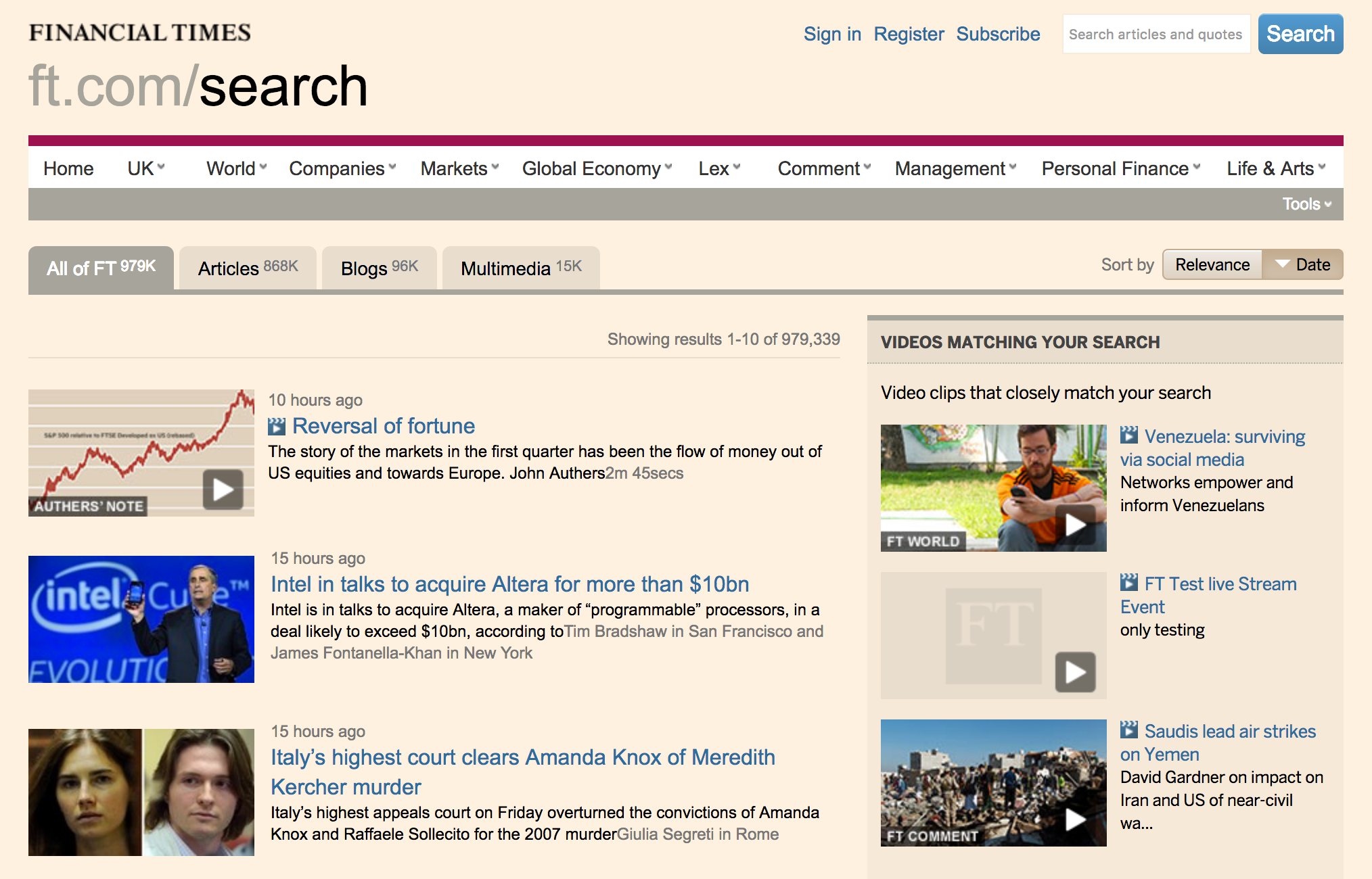
Search on the old FT.com
Google no longer sell their Site Search product so tight integration with their service is not possible. You can still link out to their simpler Custom Search service but we found that when restricted to a single domain the results didn’t always meet our expectations.
I think there are two main reasons for this:-
- The Financial Times is a news organisation and timeliness can be crucial. Whilst Google gives significant weight to recency we found articles that were 48-72 hours old often out-ranked newer posts on the same subject due to other factors in their PageRank algorithm.
- It’s really important for our users to be able to differentiate between the types of content we publish; whether they’re headlines, opinion pieces, or detailed analysis. This, along with other FT-specific prompts such as brands and authors, is information that cannot be represented by the sparse Google results page.
Of course there are plenty of alternatives to Google; Microsoft are previewing a promising custom search product and Algolia are well respected in this field amongst many others. But, we decided that we already have lots of infrastructure and an office full of clever people to play with, so we could go without adding “yet another thing” to our stack.
1.3 Elasticsearch

At the FT we use Elasticsearch (which I’ll refer to as ES) to power several projects across the organisation. If you’re not familiar, it’s a document store built on top of Lucene, an Open Source text search engine. It provides the capability to analyse and interrogate data — especially text.
On the FT.com project we use it to store and retrieve all of the content items that we make available to read online. In this role it has served 3 primary purposes:
- A cache. Our content APIs have embraced REST (the n+1 problem) and the data often needs transforming when we get it. We have one app do all of this and then push it into an ES index.
- A buffer. We’re free to add experimental features to our apps and make changes to the data without worrying about other consumers. This also means we are generally resilient against API wobbles.
- For easy access. We can use the ES search API to retrieve content in a variety of ways which are not otherwise available to us.
Although we’ve made extensive use of the last point to pull in content by type, date range, combinations of tags, and other features, these are all questions with boolean answers. Queries typed into a search field are not usually questions that can be answered with yes or no. Any search functionality must therefore do its best to understand a query, then return results that are relevant to it.
ES has the tools available to solve both of these challenges — it’s mostly a question of configuration. That said, if you’re at all familiar with the scope of the ES documentation then you’ll be aware that this is still a sizeable undertaking.
2. Full-text search
2.1 Results with relevance
When performing a full-text search with ES, each result (or hit) is returned with a score applied. The score indicates how closely the search algorithm was able to match the hit to the query. By default Lucene’s relevance function relies on a few general indicators but because we understand the structure of our content we can ask more questions to improve the quality of matches.
By design, the title and subtitle of an article must capture the essence of the piece in just a few words. Whether a reader is scanning the paper or digital page they must be articulated carefully so that the reader is able to make a quick decision about whether or not the piece is interesting to them. These fields along with the short description and our metadata system tell us what content is about. Any matches made within these fields should be given a score boost.

Salesforce has been working on algorithms to understand human language.
However, the bulk of any article is the body text and this big chunk of markup is not easily scrutable. Body text isn’t restricted to a few sentences describing the subject matter, it’s usually filled with quotes, related links, embedded media, and loads of other peripheral stuff.
Stripping away formatting and non-critical components is therefore a necessity but little else can be done to decide what amongst the remaining text is important and what isn’t. We still don’t really know how to build machines that understand human language.
For these reasons any matches made in the body text must be taken with a pinch of salt and the given score reduced.
2.2 Distance and phrases
When searching inside long fields — like the body text — matching terms may be widely spread. The distance between them can be a useful indicator when deciding whether a hit is relevant or not.
For example, a user may be looking for articles about our Prime Minister, Theresa May. Both the terms Theresa and May are somewhat meaningful on their own but ideally our search function should know that they often occur together and equate to a single thing.
If both of the terms are matched in the body text but Theresa is found in paragraph one and May in paragraph twelve then the odds of the content being about her will be close to zero.

Does the media company “21st Century Fox” ≈ Zootropolis? Not really.
To improve accuracy there are two good approaches:-
- Measure the distance between the positions of the matching terms and gradually degrade the score as the distance between the terms increases. This is named slop factor in Lucene (I do not know why.)
- When indexing, group single terms into phrases so that matches on specific phrases will score more highly. This is known as n-grams in linguistics, or shingles in Lucene (b/c roof shingles overlap… naming stuff is hard.)
In the end we chose to implement both. The latter has been very effective and has uses beyond matching (which we’ll get to later) but the former is still quite useful for sifting out the lowest quality hits.
2.3 Quality vs. quantity
It’s currently near impossible to avoid reading about Donald Trump. Sorry, not even here. He has been dominating the news agenda in recent times and just recently in the FT his name crops up in articles about industrial excavators, the gig economy, iPhones, Catalonian independence, hydrogen fuel cells and Kurdistan, to name just a few. These articles mention Trump but they are not about him.
When displaying results sorted by score these hits should receive a lowly rank and appear some pages back. But, because the name of the US president fills so many column inches each week it’s much more convenient to view the results in date order.
To avoid presenting the long tail of low quality, perhaps quite random, results to our users we implemented a minimum score rule to exclude the worst hits. This is a blunt instrument, calculated with a simple algorithm (multiplying the number of conjunctive terms against a fixed constant) but it has proven quite effective. With the algorithm in place we reduced the number of lower quality results presented to users by up to 20%.
| Month | Hits w/o filter | Hits w/filter |
|---|---|---|
| May | 625 | 539 |
| June | 521 | 419 |
| July | 468 | 403 |
| August | 548 | 476 |
| September | 460 | 372 |
| October | 457 | 388 |
Search hits for the query “Donald Trump”.
I would advise caution if you choose to implement a similar feature yourself. We found it required a number of revisions. Soon after releasing an early version of the feature, an editor’s complaint arrived in my inbox because they could not find some articles about Götland. The Swedish island had not been included in any of the fields we score highly so these articles were considered as much about it as yellow diggers, Apple products and batteries are about Trump.
2.4 AND or OR?
Our old search page defaulted to the OR operator, the spaces between search terms taken to be an implied disjunction. Any user searching with multiple terms could therefore receive results only matching one of them even if they entered five. Searching for “US tax bill” would return over 60% of all the content we’ve ever published online!
Animation by Anchor Point.
Over 90% of search queries on FT.com use just one to three terms and it’s reasonable to assume that a user expects any results presented to them to match all of them. However, if we always insisted on matching every term then each addition increases the chance of prematurely reducing the pool of results to zero. A bit like picking 6 correct lottery numbers.
For this reason it’s best for any search functionality to allow some latitude, something between a strict AND or OR. To do this we applied a sliding scale (ES supports simple expressions for this purpose) so that our search app will match a minimum number of terms and then as many as it can above that baseline.
2.5 Boolean search
Earlier I introduced our decision to use ES with a statement: “Queries typed into a search field are not usually questions that can be answered with yes or no”. But a minority of users — around 5% — do ask such questions.
Despite offering no hint that these features were available on FT.com we discovered that users had been attempting to use quotes for exact phrase matching, operators for conjunction (AND, +), disjunction (OR, |) and negation (NOT, -) and a few had even experimented with grouping combinations of these inside parentheses. Perhaps this should not be so surprising as many search engines offer this functionality.
Introducing operators turns a natural language query requiring calculation of relevance into a strict boolean where documents are scored 0 or 1. If a user enters the query “european AND union” then our search app no longer needs to measure the distance between the terms nor vary the score depending on the field, it only needs to confirm that they are both present.
Lucene supports a simple query DSL capable of handling phrases, operators and grouping with parentheses, we only needed to recognise when they are being used and switch to the appropriate algorithm. We built a parser with an expression tree builder to deconstruct the search query and flag if and how any of these features are being used.
{
left: {
type: 'phrase', text: '"Angela Merkel"', offset: 0, length: 15
},
operator: 'NOT',
right: {
type: 'word', text: 'brexit', offset: 20, length: 6
}
}3. Dealing with mistakes
3.1 Fuzziness
Rather worryingly, a little over 4% of searches on our old search page returned no results. Keen to find out why, we extracted the failed queries — but we were saved the trouble of investigating further because it was clear the majority had been caused by typos.
Implementing fuzzy matching therefore seemed to be the logical next step, by enabling it we assumed that any disarranged queries like those we’d seen would still return acceptable results.

Fuzzy matching works by generating all possible variations for a term within a defined edit distance, swapping, removing, and adding letters. The system then checks which of these generated terms it actually knows about, meaning that if I were to accidentally type “Micorsoft” into the search box I would still see results for “Microsoft” 👍.
But, as any Scrabble player or logophile will tell you, there are many thousands of word pairs in the English language so there is always a chance of returning similar — though totally incorrect — matches even when the search query is entered correctly 👎.
In the end we opted not to implement fuzzy search. Although there are options available to try and decrease the chances of mixups, we decided to simply avoid the risk and chose instead to ask the user if that’s what they really meant.
3.2 Spelling suggestions
Google has been providing “Did you mean?” suggestions for 15 years. Although many permutations of spelling errors appear around the Web it can — with confidence — make a suggestion of a more likely alternative. In a world of touch screen keyboards it’s become essential.
With ES, suggestions for unknown, or infrequent, query terms can be requested along with any matching hits. But receiving suggestions on a per-word basis means they lack context — the statistically most likely (highest scoring,) alternative may well be nonsense.
For example, a user looking for content about Tesla owner Elon Musk could miscue and enter Eoln Musk into the search box. As we don’t recognise the first term we’ll get a suggestion, but the most likely alternative is the more common Irish name, Eoin (mentioned nearly 30% more often.) We haven’t written any content about anybody called “Eoin Musk” (and I checked Facebook, there may well be nobody with this name.)

To try and disambiguate we need to not only check on a per-term basis but also the n-grams, or shingles, that we generated to help improve the recognition of names and common phrases when searching. By checking for suggestions amongst two or three term bigrams and trigrams we can receive suggestions with better certainty of their correctness.
This does mean responses can return quite a lot of noise, we will still receive suggestions for “Eoin” and maybe the European energy company “E.ON”, but we can pluck out only the longer suggestions with the highest scores to actually present to the user.
Those who are shown a suggestion on our search pages click it around 50% of the time. We need to do more research to find out if this is a good or bad statistic.
4 Conclusions
We are still in the early stages of building better search tools for FT.com and our current offering is far from perfect. We’re still in the process of learning, finding out the limitations, and responding to the curve-balls thrown at us by our users.
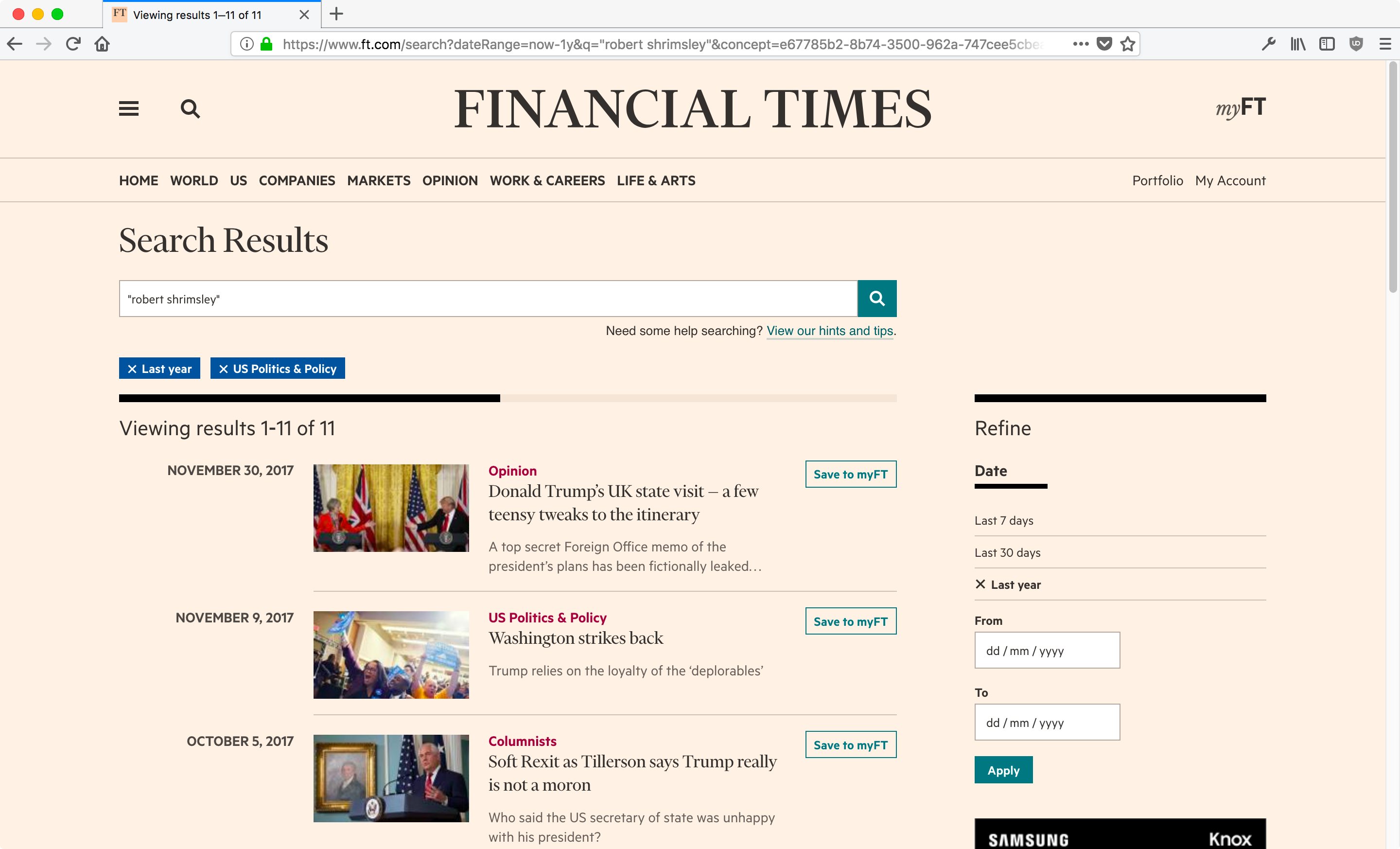
The new search page on FT.com
Since launching at the end of August the statistics and feedback have been very positive. The number of search users, searches performed, and referrals to our content pages have all been growing steadily, and on most work days our metrics are hovering around 20% above our previous highs. Complaints from users are also now few and far between.
Is it worth investing better search tools? Definitely.
I’m hoping to spend more time in future exploring new ways of improving our search features — some of the ideas we’ve been discussing include:-
- Adding a dictionary of synonyms
- Using analytics data to adjust scores based on popularity
- Trying different relevance algorithms in a multi-variant test
- Experiment with different stopwords and word stemming techniques
So, I hope this has been interesting. If you’ve taken on any similar projects recently (or know the derivation of “slop factor”) I’d love to hear about it. You can tweet me or you can leave a comment below.
🔚